- Published on
Muen Paper Scraping Website
Overview
During my internship week 2 and 3, I had the pleasure to take on two more tasks. The first one being building a small website, with a text-to-text functionality that incoperates OpenAI API, which is the focus of this blog.
The second being a research project on AI application, with a focus on AI image prediction at National Taiwan University Hospital. The goal of the second project is to predict liver tumors and nodules with DICOM images from CT scans, which I will explain further in the next blog.
What is the purpose of this tool?
The goal of this small project is a simple lookup tool. An user can input an arbitary scientific paper, then it will feed this text into chatGPT for keywords, then using a pre-populated lookup table from 4 different database websites, we will query "names" that matches the most keywords.
First, the final product. The website is simply an interface that makes it easy for users to interact with the script. Most of the complexities are within the script / backend.
Tech stack
Backend
The backend is not too complicated at all. It consists of two parts: a web-scraper for scraping the following 4 websites, and a dictionary builder and query that allows processing of these data. These are written with python.
Government Research Bulletin - 政府研究資訊系統
National Science and Technology Council - 國家科學及技術委員會補助研究計畫
Department of Research Planning and Development - 國衛院院外計畫
National Digital Library of Theses and Dissertations in Taiwan - 臺灣博碩士論文知識加值系統
Let's use the GRB site as an example:
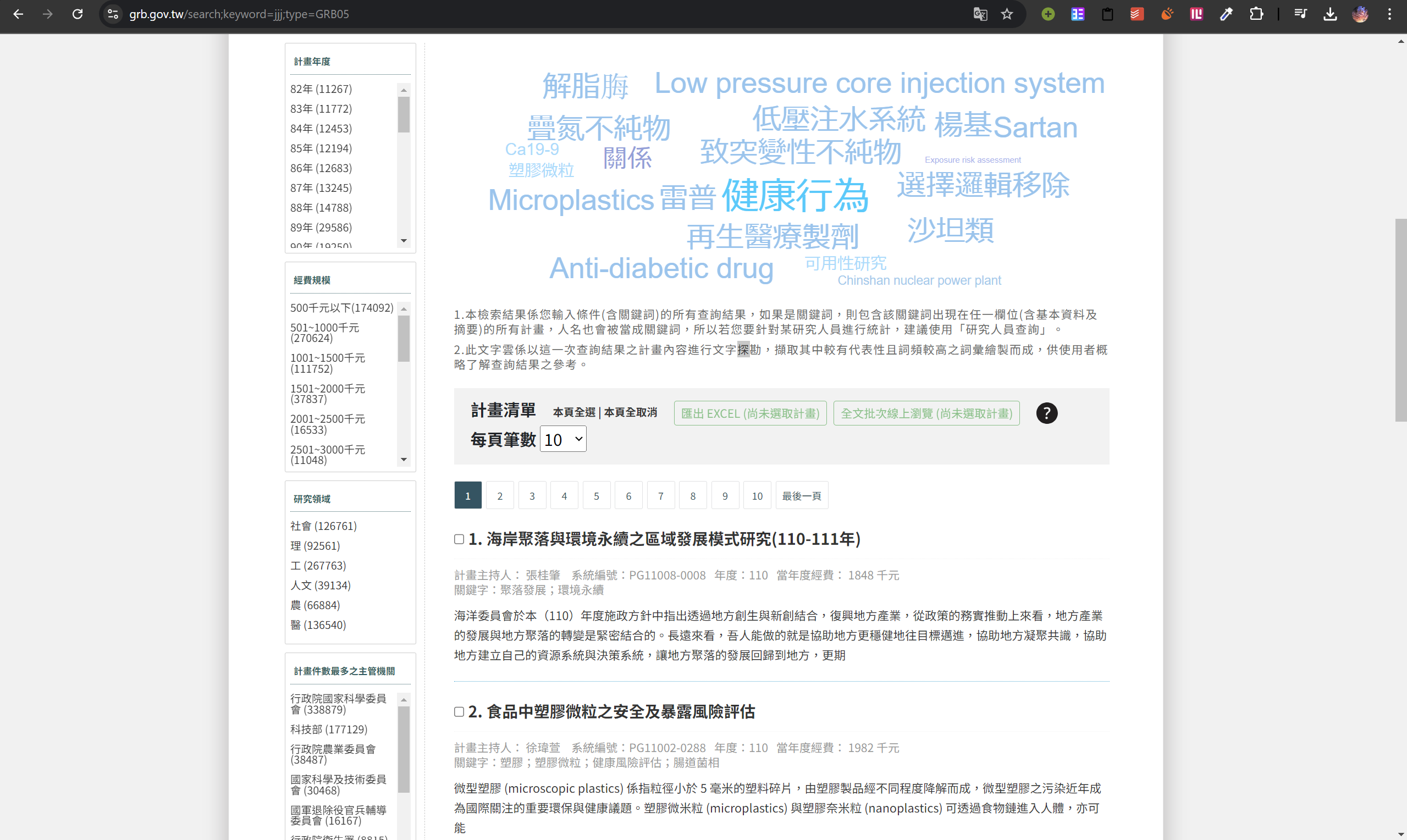
Originally, my first observation was that there is no API for any of these websites. The database is also not publically available. And the text cannot be interaacted with, unless you manually click on pages. This means beautiful soup isn't possible, and I leaned towards using selenium. Our goal is to scrape 3 things: names, keywords, and titles.
The problems are immediate. Take the GRB website for example, there seems to be some sort of anti-bot protection, or just in general a request cooldown. When using selenium to click, it will buffer for over 30 seconds randomly. On average, 10 pages take over 2 minutes.
With a total of 674461 papers to scrape, and since a maximum of 200 results can be listed at a time, this will take over
Ok sure, I can wait 11 hours...thats alright...
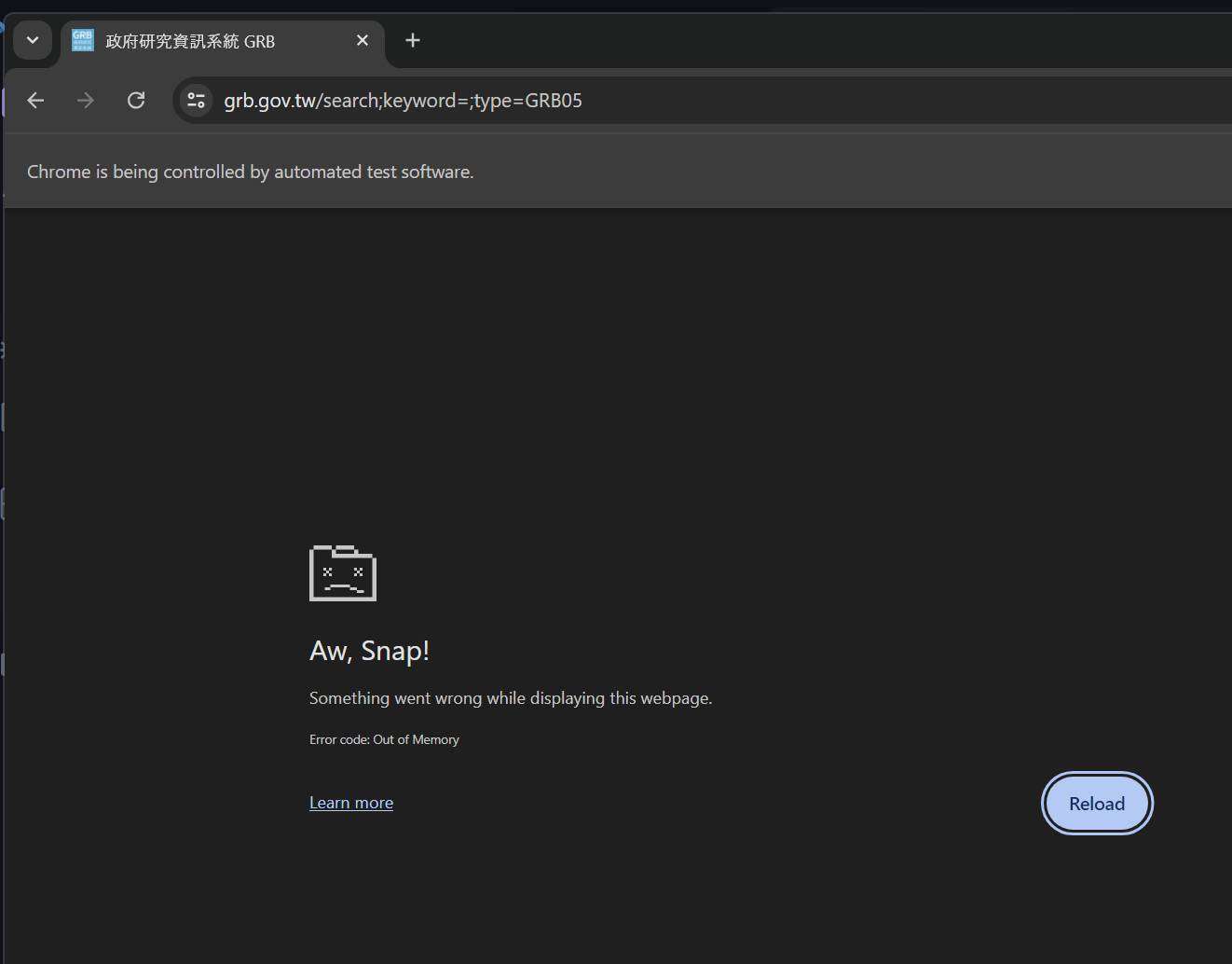
It's not alright. Turns out there's no "page select" button on any of these websites anywhere. That means if something fails to fetch, or the internet cuts out, then I have to repeat the WHOLE process. This is when I realized how inefficient this method was, and I needed a better approach.
Scraping by Post Requests
I decided to search inside developer tools (F12) to see if anything happens behind the scenes when I click the buttons on the page. I knew there has to be some backend fetching the data from their database (to be fair this should've been the first thing I did).
Sure enough, there is an API call called "searcher" in the requests list tab. It seems to contain the data that I want in json format, which is perfect.
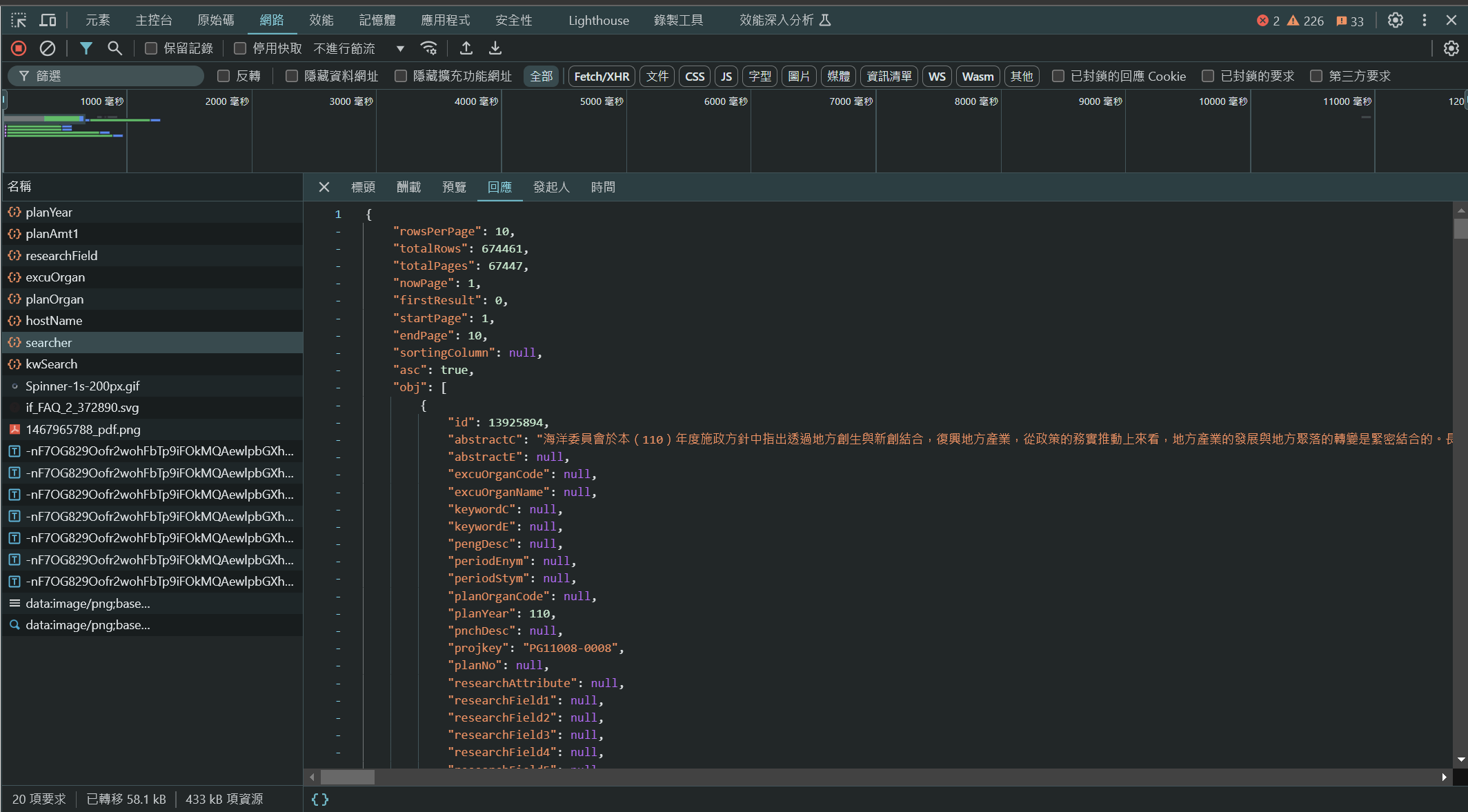
Now all I have to do is copy what the website is sending to its backend. I sent a post request that allows me to query by page and keyword.
With this new method, 1 page takes around 0.6s, which is very fast, and even if my code fails, I will be able to continue querying from where I left off.
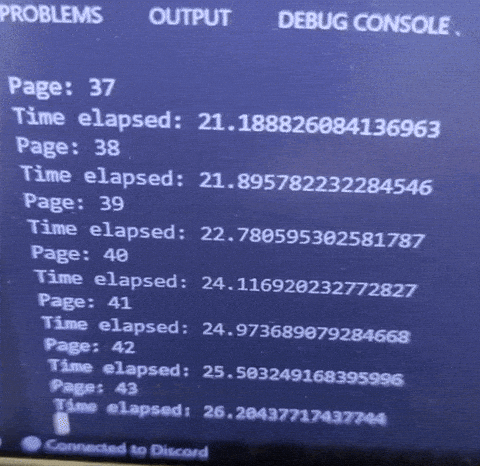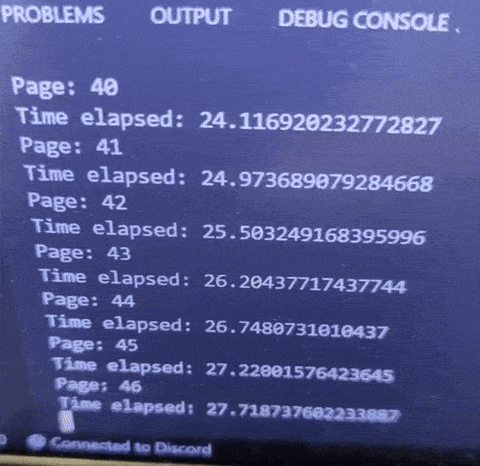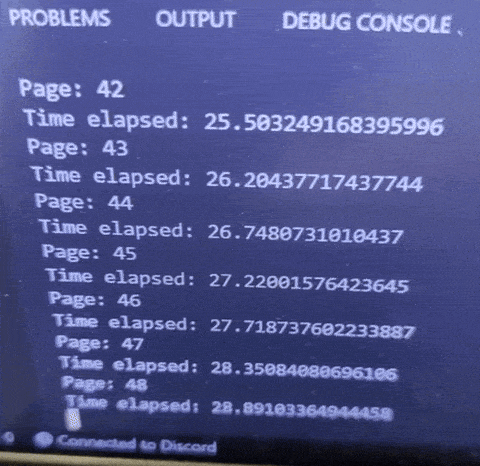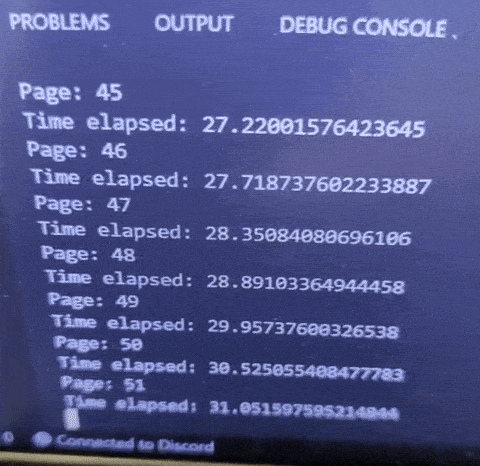
In total, this will now only take around
This is a 95% improvement over the previous method. Great success!
search.py
The other half of the problem isn't complicated either. After scraping the websites, the data is stored in a .json file. To achieve fast lookup, I simply store the keywords as dictionaries. To get the keywords for lookup, I simply feed the paper name into GPT 3.5, and asks it to return 10 keywords. Then I sort the cumulative occurances that each name shows up when queried with my keywords. Essentially, I want to know who is most relevant in the field related to a specific paper.
Frontend
The webpage is built with Next.js + React + Tailwind CSS, and deployed on Vercel. I wanted to try the new AI powered UI generation tool from vercel called v0.dev. It was able to give me a pretty nice template to work. The difficult part is mostly hooking the UI to the backend, which I used Flask to handle API requests.
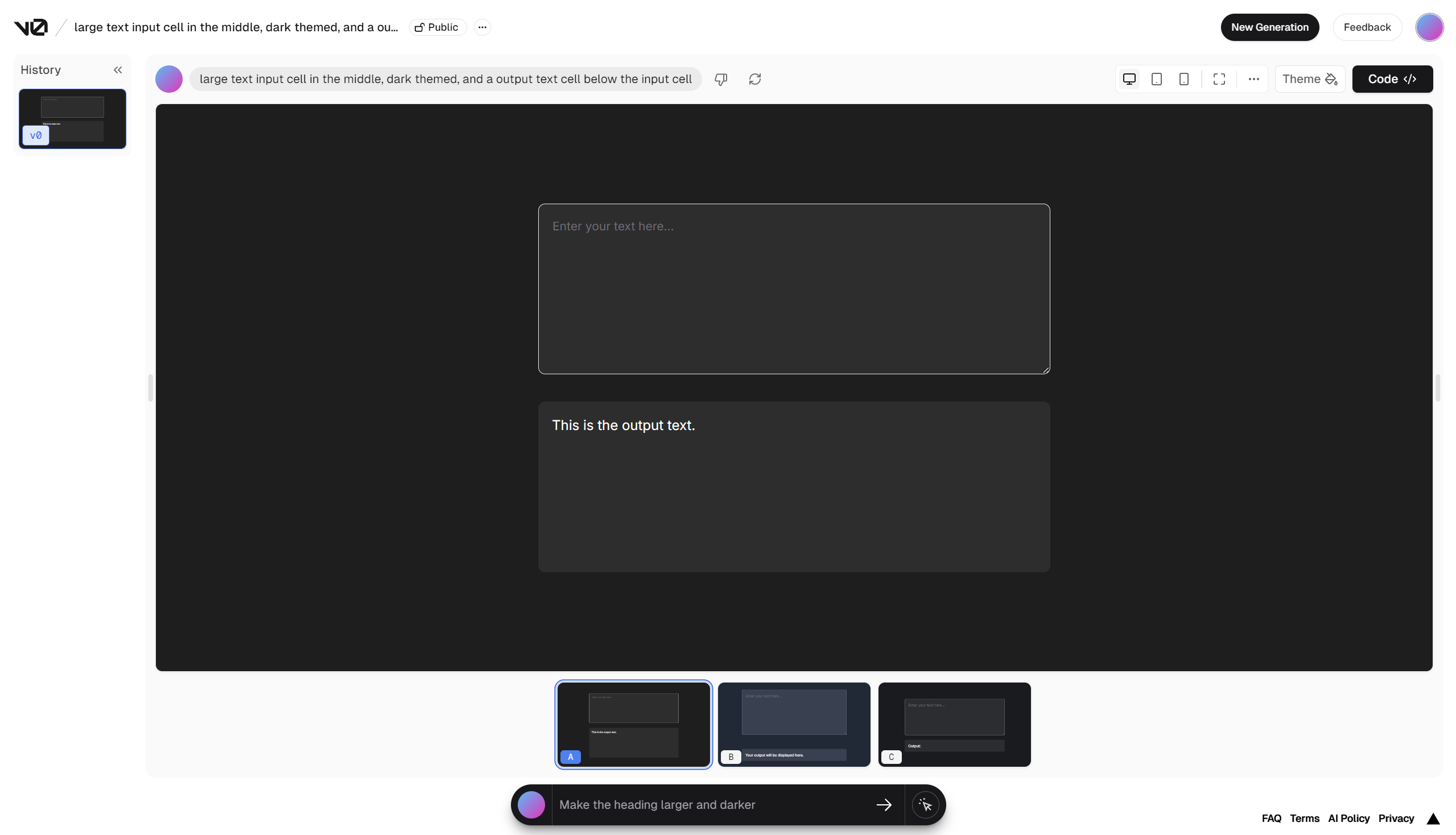
Since the react code isn't that important in my opinion, I will omit it for now. You can view the source code here. Hope you enjoyed reading!